Techniki eksploracji danych
Wgląd w 26 technik analizy Big Data: część 2
Do tej pory na moich blogach o Big Data zapoznawałem Cię z różnymi aspektami Big Data, od tego, co to właściwie oznacza, do faktów, nakazów i zakazów. W poprzednim blogu widzieliśmy kilka technik Big Data Analytics. Idąc dalej na tym blogu.
Rozpoznawanie wzorców
Rozpoznawanie wzorców to gałąź uczenia maszynowego, która koncentruje się na rozpoznawaniu wzorców i prawidłowości w danych, chociaż w niektórych przypadkach jest uważana za prawie równoznaczną z uczeniem maszynowym. Systemy rozpoznawania wzorców są w wielu przypadkach szkolone na podstawie oznaczonych danych „uczących” (uczenie nadzorowane), ale gdy nie są dostępne żadne oznaczone dane, można użyć innych algorytmów do wykrywania wcześniej nieznanych wzorców (uczenie nienadzorowane).
Modelowanie predykcyjne
Analityka predykcyjna obejmuje różne techniki, które przewidują przyszłe wyniki na podstawie danych historycznych i bieżących. W praktyce analitykę predykcyjną można zastosować w niemal wszystkich dyscyplinach – od przewidywania awarii silników odrzutowych na podstawie strumienia danych z kilku tysięcy czujników, po przewidywanie kolejnych ruchów klientów na podstawie tego, co kupują, kiedy kupują, a nawet czego mówią w mediach społecznościowych. Techniki analizy predykcyjnej opierają się przede wszystkim na metodach statystycznych.
Zobacz też: Przewodnik dla początkujących po analizie Big Data
Analiza regresji
Jest to technika, która wykorzystuje zmienne niezależne i ich wpływ na zmienne zależne. Może to być bardzo przydatna technika do określania analiz mediów społecznościowych, takich jak prawdopodobieństwo znalezienia miłości na platformie internetowej.
Analiza nastrojów
Analiza nastrojów pomaga naukowcom określić nastroje mówców lub pisarzy w odniesieniu do tematu. Analiza nastrojów pomaga:
Popraw obsługę w sieci hoteli, analizując komentarze gości.
Dostosuj zachęty i usługi do tego, o co naprawdę proszą klienci.
Określ, co naprawdę myślą konsumenci na podstawie opinii z mediów społecznościowych.
Przetwarzanie sygnałów
Przetwarzanie sygnału to technologia umożliwiająca, która obejmuje podstawową teorię, aplikacje, algorytmy i implementacje przetwarzania lub przesyłania informacji zawartych w wielu różnych formatach fizycznych, symbolicznych lub abstrakcyjnych, szeroko określanych jako sygnały . Wykorzystuje matematyczne, statystyczne, obliczeniowe, heurystyczne i lingwistyczne reprezentacje, formalizmy i techniki reprezentacji, modelowania, analizy, syntezy, odkrywania, odzyskiwania, wykrywania, pozyskiwania, ekstrakcji, uczenia się, bezpieczeństwa lub kryminalistyki. Przykładowe zastosowania obejmują modelowanie do analizy szeregów czasowych lub implementację fuzji danych w celu określenia dokładniejszego odczytu poprzez połączenie danych z zestawu mniej precyzyjnych źródeł danych (tj. wyodrębnienie sygnału z szumu).
Analiza przestrzenna
Analiza przestrzenna to proces, dzięki któremu surowe dane przekształcamy w przydatne informacje. Jest to proces badania lokalizacji, atrybutów i relacji cech w danych przestrzennych za pomocą nakładek i innych technik analitycznych w celu odpowiedzi na pytanie lub zdobycia przydatnej wiedzy. Analiza przestrzenna wyodrębnia lub tworzy nowe informacje z danych przestrzennych.
Statystyka
W statystyce eksploracyjna analiza danych to podejście do analizy zbiorów danych w celu podsumowania ich głównych cech, często metodami wizualnymi. Model statystyczny może być używany lub nie, ale przede wszystkim EDA służy do sprawdzenia, co dane mogą nam powiedzieć poza formalnym modelowaniem lub testowaniem hipotez. Techniki statystyczne są również stosowane w celu zmniejszenia prawdopodobieństwa błędów typu I („fałszywie dodatnie”) i błędów typu II („fałszywie ujemne”). Przykładem aplikacji są testy A/B mające na celu określenie, jakie rodzaje materiałów marketingowych najbardziej zwiększą przychody.
Zobacz też: 40 zadziwiających faktów na temat Big Data
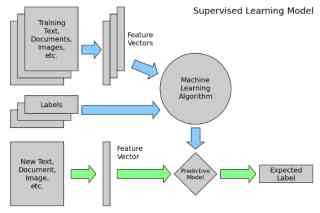
Nadzorowana nauka
Uczenie nadzorowane to zadanie uczenia maszynowego polegające na wywnioskowaniu funkcji na podstawie oznaczonych danych szkoleniowych. Dane uczące składają się z zestawu przykładów uczących . W uczeniu nadzorowanym każdy przykład jest parą składającą się z obiektu wejściowego (zwykle wektora) i pożądanej wartości wyjściowej (nazywanej również sygnałem nadzorczym ). Nadzorowany algorytm uczenia analizuje dane treningowe i tworzy wywnioskowaną funkcję, która może być wykorzystana do mapowania nowych przykładów.
Analiza sieci społecznościowych
Analiza sieci społecznościowych to technika, która została po raz pierwszy zastosowana w branży telekomunikacyjnej, a następnie szybko zaadoptowana przez socjologów do badania relacji międzyludzkich. Obecnie jest stosowany do analizy relacji między ludźmi w wielu dziedzinach i działalności komercyjnej. Węzły reprezentują jednostki w sieci, podczas gdy powiązania reprezentują relacje między jednostkami.
Symulacja
Modelowanie zachowania złożonych systemów, często wykorzystywane do prognozowania, przewidywania i planowania scenariuszy. Na przykład symulacje Monte Carlo to klasa algorytmów, które opierają się na powtarzającym się losowym próbkowaniu, tj. uruchamianiu tysięcy symulacji, z których każda oparta jest na innych założeniach. Wynikiem jest histogram, który przedstawia rozkład prawdopodobieństwa wyników. Jednym z zastosowań jest ocena prawdopodobieństwa osiągnięcia celów finansowych, biorąc pod uwagę niepewność co do powodzenia różnych inicjatyw
Analiza szeregów czasowych
Analiza szeregów czasowych obejmuje metody analizy danych szeregów czasowych w celu wyodrębnienia znaczących statystyk i innych cech danych. Dane szeregów czasowych często powstają podczas monitorowania procesów przemysłowych lub śledzenia korporacyjnych wskaźników biznesowych. Analiza szeregów czasowych uwzględnia fakt, że punkty danych zebrane w czasie mogą mieć wewnętrzną strukturę (taką jak autokorelacja, trend lub zmienność sezonowa), którą należy uwzględnić. Przykładami analizy szeregów czasowych są godzinowa wartość indeksu giełdowego lub liczba pacjentów, u których dana choroba jest diagnozowana każdego dnia.
Nauka nienadzorowana
Uczenie nienadzorowane to zadanie uczenia maszynowego polegające na wywnioskowaniu funkcji opisującej ukrytą strukturę z danych nieoznaczonych. Ponieważ przykłady podane uczniowi są nieoznaczone, nie ma sygnału błędu ani nagrody do oceny potencjalnego rozwiązania – to odróżnia uczenie się bez nadzoru od uczenia nadzorowanego i uczenia się przez wzmacnianie.
Jednak uczenie nienadzorowane obejmuje również wiele innych technik, które mają na celu podsumowanie i wyjaśnienie kluczowych cech danych.
Wyobrażanie sobie
Wizualizacja danych to przygotowanie danych w formacie obrazkowym lub graficznym. Umożliwia decydentom zobaczenie analiz przedstawionych w formie wizualnej, dzięki czemu mogą uchwycić trudne koncepcje lub zidentyfikować nowe wzorce. Dzięki interaktywnej wizualizacji możesz pójść o krok dalej, korzystając z technologii, aby zagłębić się w wykresy i wykresy w celu uzyskania bardziej szczegółowych informacji, interaktywnie zmieniając wyświetlane dane i sposób ich przetwarzania.
Wniosek
Analityka Big Data to jeden z najważniejszych przełomów w branży technologii informatycznych. W rzeczywistości Big Data pokazało swoje znaczenie i potrzebę niemal we wszystkich sektorach i we wszystkich działach tych branż. Nie ma ani jednego aspektu życia, który nie zostałby dotknięty przez Big Data, nawet nasze życie osobiste. Dlatego potrzebujemy Big Data Analytics, aby efektywnie zarządzać tymi ogromnymi ilościami danych.
Jak wspomniano wcześniej, ta lista nie jest wyczerpująca. Naukowcy wciąż eksperymentują nad nowymi sposobami analizowania tych ogromnych ilości danych, które są obecne w różnych formach, których szybkość generowania wzrasta z czasem, aby uzyskać wartości dla naszych konkretnych zastosowań.
Wizualna eksploracja danych
Dr Sławomir Strzykowski, Senior Business Solutions Manager, SAS Institute

Termin “wizualna eksploracja danych” staje się coraz bardziej synonimem nowoczesnego myślenia w biznesie. Wydobywanie wiedzy ze zbiorów danych poprzez połączenie tradycyjnych metod analizy z zaawansowanymi metodami prezentacji wizualnej jest w czasach „Big Data” oraz „Internet of Things” nie tylko potrzebą, ale przede wszystkim jednym z ważniejszych kryteriów rozwoju firmy, wyboru strategii konkurencyjnej oraz trafności podejmowanych decyzji biznesowych.
Tempo przemian w gospodarkach, dynamika rozwoju kolejnych – dotychczas nieistniejących form biznesu (np. handel elektroniczny B2B, B2C, C2C, C2B) – sekundowe czasy dostępu do informacji w erze szybkiego Internetu – to tylko niektóre czynniki, które powodują konieczność zastosowania narzędzi do wizualnej eksploracji danych oraz możliwości tworzenia interaktywnych raportów, udostępnianych na rosnącą ilość urządzeń mobilnych.
Wyzwania, które biznes musi adresować w obecnych czasach mają naturę wielowymiarową a dane – pozyskiwane z ustrukturyzowanych i nieustrukturyzowanych źródeł – zbyt duży zakres i objętość, by poradzić sobie w tradycyjny sposób z ich interpretacją. Dodatkowo, wgląd w dane musi mieć określony cel (strategiczny, operacyjny, długo/krótko terminowy) i w konsekwencji doprowadzić do podjęcia działań. Działań, które dzięki użyciu wizualnej eksploracji danych będą szybsze, bardziej trafne oraz adekwatne do zmieniającego się otoczenia biznesowego…
Wizualizacja – początki…
W jaskini w pobliżu indonezyjskiej miejscowości Maros na wyspie Sulawesi odkryto malowidła, wizualizujące świat człowieka sprzed 40.000 lat. Sceny z życia ówczesnych ludzi stanowią do dzisiaj ślad niewyobrażalnie dalekiej przeszłości, w której otaczająca człowieka przyroda i rodząca się cywilizacja dostarczała zupełnie innych danych. Te dane, stanowiące źródło poznania, ówczesny człowiek zmieniał na informacje (nadając danym odpowiedni kontekst), a następnie wykorzystywał usystematyzowane informacje jako wiedzę. Z tej wiedzy pochodziła mądrość, która doprowadziła człowieka do Nowej Ery Danych, w których zmieniły się narzędzia do wizualizacji danych, ale przekaz pozostaje taki sam…
Eksploracja – początki
Człowiek od początku swojego istnienia eksplorował świat. U źródeł tej eksploracji leżała ciekawość (co jest za horyzontem?), konieczność (brak pożywienia, demografia, zmieniające się warunki naturalne) lub żądza (chcę mieć więcej). Niezależnie jednak od pobudek, eksploracja wyzwalała i wciąż wyzwala potrzebę odkrywania – odkrywania przyczyn, związków i zależności, pozwalając jednocześnie prognozować i podejmować decyzje. Eksploracja danych dzisiaj jest kontynuacją drogi, którą wybraliśmy jako cywilizacja u jej początków. Wciąż przystosowujemy się do świata i przystosowujemy świat do siebie, reagując na zmiany rynkowe, potrzeby klientów i odpowiadając na wyzwania, które stawia przed nami otoczenie konkurencyjne…
Eksploracja wizualna – dzisiaj…
Dynamika zmian w biznesie w erze Web 2.0 wymaga ciągłej analizy nowych typów danych, które muszą uzyskać kontekst biznesowy. Tylko w takim wypadku jest możliwe określanie np. nowych potrzeb klientów, analiza sentymentów oparta na sieciach społecznościowych lub zapewnienie mobilności pracowników z zachowaniem dostępu do istotnych dla biznesu wskaźników.
Z drugiej strony ograniczone budżety wymagają przekonstruowania dotychczasowego modelu, opartego na silnych, scentralizowanych działach IT, które są odpowiedzialne między innymi za dostarczanie analiz do końcowych użytkowników. Użycie samoobsługowego serwisu analitycznego, wyposażonego w intuicyjny interfejs umożliwiający pobieranie danych z różnych źródeł, z nałożonym na wyniki kontekstem biznesowym jest rozwiązaniem, które w krótkim czasie nie tylko przyniesie zwrot z inwestycji, ale również zmieni postrzeganie roli danych wewnątrz i na zewnątrz organizacji.
Trend związany z coraz częstszym wykorzystywaniem wizualnej eksploracji danych ma też uzasadnienie w liczbach.
W Polsce mamy 25,7 mln użytkowników Internetu. 67% populacji w kraju ma dostęp do Internetu, a 13 milionów (34% populacji) aktywnie korzysta z mediów społecznościowych. Ponad 56 milionów urządzeń mobilnych jest używanych przez Polaków. 24 % z nich korzysta aktywnie z mobilnych aplikacji społecznościowych.
Mobilność, interaktywność oraz bezpieczeństwo – to podstawowe wymogi dla każdego narzędzia do wizualnej eksploracji danych. Ale to nie wszystko…
Obliczenia analityczne są najbardziej wrażliwą - ze względu na możliwie długi czas przetwarzania – warstwą rozwiązań tego typu rozwiązań. Tylko narzędzia oferujące środowisko masowego przetwarzania równoległego (MPP) oraz technologii in-memory mogą zmierzyć się z naprawdę olbrzymim wolumenem danych.
A wszystko to nie jest w stanie zdarzyć się bez człowieka i jego zmysłów…
Człowiek 4.0 - homo visual
70% receptorów sensorycznych znajduje się w naszych oczach. Ludzki mózg przeznacza 25% swojej mocy na obsługę warstwy wizualnej. Siatkówka oka przetwarza informacje z przybliżoną prędkością 10 Mbps. Do 2020 roku Internet rozrośnie się do poziomu 45 Zettabajtów…
Zawód „Data Scientist” będzie jednym z najbardziej pożądanych zawodów w IT w ciągu najbliższej dekady…
To właśnie człowiek – „Data Scientist” będzie odgrywał decydującą rolę w tworzeniu nowej rzeczywistości wizualnej. Wyposażony w odpowiednie rozwiązanie, znakomicie poruszający się po dostępnych źródłach danych, umiejący osadzić wyniki zastosowanej analityki w kontekście biznesowym – człowiek 4.0 eksplorujący świat w nowych wymiarach…
Technologia
Na naszych oczach rozpoczęła się nowa era wizualizacji i analityki o wysokiej wydajności. Oprócz Data Scientists, również przedstawiciele kadry zarządzającej potrzebują przystępnych i atrakcyjnych graficznie narzędzi, które pozwolą im błyskawicznie zrozumieć sens prezentowanych danych i podjąć właściwe decyzje. Zdolność do szybkiego i efektywnego przetwarzania danych i przełożenia uzyskanych wyników na wzrost przychodów, produktywności, czy udziałów w rynku – decyduje dziś o przewadze konkurencyjnej. Przedsiębiorstwa coraz częściej sięgają po sprawdzone rozwiązania, takie jak SAS Visual Analytics. To narzędzie łączy w sobie moc zaawansowanego analizowania dużych wolumenów danych (High-Performance Analytics) oraz łatwego w obsłudze i wizualnie przyjaznego interfejsu eksploracji danych. Jest to analityka dostępna dla każdego, wykonywana automatycznie, bez żadnego kodowania, z wyjaśnieniami co dany wynik oznacza. Można ją zastosować zarówno w mniejszej wielkości firmach, jak i dużych organizacjach przetwarzających dane na skalę masową.
Wizualna eksploracja danych – quo vadis?
W czasach tak gwałtownego wzrostu danych, przy jednoczesnym ujednoliceniu przestrzeni rynkowych (globalizacja biznesu, powszechność usług, „ponadnarodowość” klientów i partnerów w sieci) pytanie o przyszłość wizualnej eksploracji danych może być ryzykowne. Przestrzeń naszych zmysłów (podobnie jak horyzont czasu ) pozostaje wciąż polem do eksploracji. Miniaturyzacja urządzeń mobilnych wplecionych w rozwiązania „Internet of Things” w coraz większym stopniu będą wymagać wizualizowania. Człowiek 4.0 będzie podążał swoją drogą, odbywając podróż przez Ocean Big Data… Rozwiązania SAS Institute będą towarzyszyć tej podróży… - dołącz do nas już dzisiaj…
Tematyce nowoczesnej wizualizacji danych poświęcona jest najnowsza publikacja firmy SAS. E-book „4 powody, dla których nie możesz się obyć bez wizualizacji danych” jest dostępny bezpłatnie na stronie internetowej firmy SAS.
Rozwiązanie – SAS® Visual Analytics SAS® Visual Analytics to wysoce wydajne i łatwe w obsłudze rozwiązanie do szybkiej i kompleksowej analizy danych, w tym również „Big Data”. W porównaniu z klasycznymi narzędziami Business Intelligence, pozwala szerokiej grupie użytkowników na znacznie szybszy dostęp do danych i informacji zgromadzonych w firmie. Eksploracja dużych ilości danych przez wielu użytkowników w tym samym czasie połączona z zaawansowaną analityką oferowaną przez SAS daje organizacjom możliwość wydobycia niedostępnej do tej pory, często nieoczekiwanej wiedzy, rozwiązania złożonych problemów biznesowych oraz szybszego zidentyfikowania nowych, lepszych kierunków działań. Rysunek 1 SAS Visual Analytics – przykładowy zestaw wizualizacji danych Wizualna eksploracja danych w ciągu sekund… W SAS® Visual Analytics interaktywne analizy danych, wizualne poszukiwanie nieznanych relacji i wzorców, odkrywanie nieprawidłowości lub wyjątków dostępne są dla każdego użytkownika biznesowego bez konieczności programowania czy intensywnych szkoleń. Unikalne funkcje, takie jak automatyczny dobór najlepszego sposobu prezentacji; graficzne, interaktywne filtrowanie, wizualizacje geograficzne, grafów, sieci; czy też podpowiedzi „Co to znaczy?" sprawiają, że rozwiązanie jest niezwykle łatwe w obsłudze i pozwala na szybkie uzyskiwanie wyników i ich interpretację. Rysunek 2 Wykres Sankeya jako przykład eksploracji danych w SAS Visual Analytics Raporty – w każdym miejscu i w każdym czasie… Łatwy w obsłudze, intuicyjny dostęp w SAS® Visual Analytics do raportów i analiz z możliwością interaktywnego drążenia, wybierania i filtrowania danych, przechodzenia od ogółu do szczegółu, samodzielnego poszukiwania odpowiedzi na nasuwające się pytania biznesowe, bez potrzeby posiadania zaawansowanych umiejętności informatycznych. Wysoka skalowalność i wydajność niezależnie od rozmiaru używanych danych oraz liczby użytkowników dzięki zastosowaniu technologii in-memory. Rysunek 3 Przykład wykresu korelacji w raporcie SAS Visual Analytics Dobrze dobrany zestaw metod analitycznych pozwala wszystkim użytkownikom wykroczyć poza świat standardowych raportów i dashboardów. Wykonanie prognozy z wyborem najlepszego modelu szeregu czasowego, sprawdzenie zmiany wyniku prognozy po zmianie wartości zmiennych niezależnych (analizy what - if) lub też wykorzystanie metody drzew decyzyjnych do wykrycia zależności między danymi pozwala na znacznie głębsze zrozumienie swoich danych niż jest to możliwe za pomocą klasycznych narzędzi Business Intelligence. Rysunek 4 Przykład prognozy w SAS Visual Analytics Gdziekolwiek jesteś – w każdym miejscu i każdym czasie… Błyskawiczne udostępnianie raportów w SAS® Visual Analytics na urządzenia mobilne zapewnia ciągłą kontrolę kluczowych dla biznesu wskaźników. Dotykowy interfejs, intuicyjna nawigacja oraz samoobsługowa aktualizacja zapewnia komfort pracy oraz pozwala podejmować natychmiastowe decyzje. I jeszcze jedno… Polski interfejs. Dostęp do danych społecznościowych (Twitter®, Facebook®, Google Analytics®) wprost z SAS® Visual Analytics. Integracja z Microsoft Office®. Dostępny również w chmurze. Więcej...
Rozpowszechnianie niniejszego artykułu możliwe jest tylko i wyłącznie zgodnie z postanowieniami „Regulaminu korzystania z artykułów prasowych” i po wcześniejszym uiszczeniu należności, zgodnie z cennikiem © ℗
Techniki eksploracji danych
Techniki „Data Mining”
Eksploracja danych nie jest nowym wynalazkiem, który pojawił się w erze cyfrowej. Ta koncepcja istnieje od ponad wieku, ale w latach 30. XX wieku stała się bardziej publiczna. Eksploracja danych to proces odkrywania wzorców w dużych zestawach danych obejmujących wykorzystywanie algorytmów (zwane często tajemniczo "uczeniem maszynowym"), statystyki i systemów baz danych. Pojęcie „eksploracja danych” jest mylące, ponieważ celem jest ekstrakcja wzorców i wiedzy z dużych ilości danych, a nie ekstrakcja samych informacji. Szukamy najczęściej wzorca nie gotowej informacji. Jest to również modne, pojemne hasło i jest często stosowane do dowolnej formy przetwarzania danych lub informacji.
Przejdźmy zatem przez spis najczęściej używanych technik stosowanych w eksploaracji danych („data mining”). Sam temat „data mining” jest na tyle pojemny że można by napisać o nim co najmniej kilka stron. Na nasze potrzeby przyjmijmy, że jest to po prostu praca z danymi. A w tej pracy stosujemy najczęściej techniki wymienione poniżej w akapicie „Techniki Data Mining”.
Mając ogólne pojęcie co kryje się za daną metodą pracy z danymi, przejdziemy do zastosowania tej wiedzy w praktyce. W innym artykule, „Machine learning na przykładach", pojawią się konkretne przypadki zastosowania algorytmów do rozwiązania z życia wziętych problemów i odpowiedzi na często stawiane pytania w biznesie.
1. Predykcja (prediction)
Klasyfikacja i Regresja to techniki eksploracji danych wykorzystywane do rozwiązywania podobnych problemów. Oba są używane w analizie predykcyjnej, ale regresja jest używana do przewidywania wartości numerycznej lub ciągłej, podczas gdy klasyfikacja używa etykiet by przypisać dane do odrębnych kategorii (klas).
Klasyfikacja
Klasyfikacja to przypisanie obiektu do określonej klasy na podstawie jego podobieństwa do poprzednich przykładów innych obiektów. Zazwyczaj klasy wzajemnie się wykluczają.
Przykładowym pytaniem klasyfikacyjnym byłoby „Którzy z naszych klientów odpowiedzą na naszą ofertę” i stworzenie dwóch klas: „zareagują na ofertę” oraz „odrzucą ofertę”.
Inny przykładowy model klasyfikacji - ryzyko kredytowe. Mogłoby zostać opracowane na podstawie obserwowanych danych dla wnioskodawców kredytowych w pewnym okresie czasu. Możemy śledzić historię zatrudnienia, posiadanie domu lub wynajem, długość zamieszkania, rodzaj inwestycji i tak dalej. Docelowymi klasami byłby rating kredytowy; np. „niski” i „wysoki”.
Atrybuty (np. historia zatrudnienia) nazwiemy mądrze „predyktorami” (albo „zmiennymi niezależnymi” a docelowe zmienne „zmiennymi zależnymi” lub po prostu „klasami”. Klasyfikacja należy do ‘nadzorowanych’ metod. Czym są metody nadzorowane czytaj w „Metody nadzorowane i metody nienadzorowane" poniżej.
Regresja
Regresja to „szacowanie wartości”. Jest to określenie związku pomiędzy różnymi wielkościami i na tej podstawie próbowanie oszacowania („przewidzenia”) nieznanych wartości. Na przykład: skoro znamy obrót firmy z poprzedniego roku, miesiąc po miesiącu, i znamy wydatki na reklamę w każdym miesiącu poprzedniego roku to jesteśmy w stanie, zakładając wydatkowanie pewnej kwoty na reklamę w następnym roku, oszacować wielkość przychodu.
Innym pytaniem na które możemy poznać odpowiedź używając regresji może być „Jak często dany klient skorzysta z usługi?”
2. Współwystępowanie i połączenia
Odkrywanie grup lub odkrywanie asocjacji próbuje znaleźć powiązania między obiektami bazując na transakcjach tych obiektów. Dlaczego chcemy znaleźć takie wystąpienia? Reguły asocjacji podpowiedzą nam „klienci, którzy kupili nowy eWatch, kupili także głośnik Bluetooth.” Algorytmy wyszukiwania wzorców sekwencji mogą sugerować jak powinna być zorganizowana akcja serwisowa czy obsługa klienta.
Asocjacja
Asocjacja to metody odkrywania interesujących zależności lub korelacji, nazywanych ogólnie asocjacjami, pomiędzy danymi w zbiorach danych. Relacje między elementami są wyrażone jako reguły asocjacji. Reguły asocjacyjne są często używane do analizy transakcji sprzedaży. Na przykład można zauważyć że, „klienci, którzy kupują płatki zbożowe w sklepie spożywczym, często kupują mleko w tym samym czasie” (eureka!).
Na przykład w e-commerce reguły asocjacji mogą być używane do personalizacji stron internetowych. Model asocjacyjny może odkryć że, „użytkownik odwiedzający strony A i B może w 70% odwiedzić także stronę C w tej samej sesji”. Na podstawie tej reguły można utworzyć dynamiczne łącze dla użytkowników, którzy mogą być zainteresowani stroną C.
Wyszukiwanie wzorców
Wyszukiwanie wzorców (patterns), częściej konkretnie wzorców sekwencyjnych (sequential patterns), to wyszukiwanie uporządkowanych sekwencji. Ważna jest kolejność sekwencji między elementami. Wyszukane wzorce prezentowane są w kolejności ‘wsparcia’ czyli częstotliwości wystąpienia danego wzorca w zbiorze elementów w stosunku do ilości rozważanych transakcji.
3. Klastrowanie
Klastrowanie (clustering) to grupowanie obiektów o podobnych właściwościach. W wyniku tej operacji powstaje klaster lub klasa. Klastrowanie może udzielić nam odpowiedzi na pytanie „czy nasi klienci tworzą grupy lub segmenty?” I w konsekwencji „jak powinny wyglądać nasze zespoły obsługi klienta (lub zespoły sprzedaży) by do nich się dostosować?”.
Klastrowanie, podobnie jak klasyfikacja, służy do segmentowania danych. W przeciwieństwie do klasyfikacji, grupowanie modeli w segmenty dzieli dane na grupy, które nie były wcześniej zdefiniowane.
Klastrowanie należy do ‘nienadzorowanych’ metod. Czym są metody nienadzorowane czytaj w ‘Metody nadzorowane i metody nienadzorowane’ poniżej.
Metody nadzorowane i metody nienadzorowane.
Inaczej uczenie nadzorowane i uczenie nienadzorowane. W uczeniu nadzorowanym stawiamy konkretny cel – spodziewamy się określonego wyniku. Na przykład:
„Czy możemy znaleźć grupy klientów, którzy mają szczególnie wysokie prawdopodobieństwo anulowania ich usługi wkrótce po wygaśnięciu ich umów? ”
Albo:
„Podzielmy klientów ze względu na ryzyko niewypłacalności; małe, średnie, duże.”
Przykłady metod nadzorowanych to klasyfikacja i regresja. Używane tutaj często algorytmy to decision tree, logistic regression, random forest, support vector machine, K-nearest neighbors.
W uczeniu nienadzorowanym nie stawiamy sobie konkretnego celu – nie spodziewamy się określonego wyniku docelowego. Stawiane tutaj pytania to np:
„Czy nasi klienci tworzą różne grupy?”
Przykłady metod nienadzorowanych to grupowanie (clustering) i korelacja (association). W przenośni nauczyciel „nadzoruje” ucznia starannie dostarczając informacje o celu wraz z zestawem przykładów. Nienadzorowane zadanie edukacyjne może obejmować ten sam zestaw ćwiczeń ale nie zawiera informacji o celu - uczący się nie otrzyma informacji o celu nauki ale ma sformułować własne wnioski z informacji, które otrzymał.
Po prostu algorytmy
Cała tajemniczość „maszin lerning” narodziła się z braku łatwego dostępu do funkcji/algorytmów, które wykonują pracę opisaną powyżej. Same narzędzie są dostępne na rynku od lat. Co więcej, są często darmowe! By jednak z nich korzystać potrzebna jest choćby podstawowa wiedza z zakresu baz danych, programowania, języka SQL, parsowania plików – dane najczęściej wymagają sformatowania do odpowiedniej postaci, by móc z nich skorzystać.
Wszystkie te obliczenia możliwe są dzięki odpowiednim algorytmom. Większość z tych obliczeń mogła być dokonana dekady a nawet więcej lat wcześniej(!). Algorytm regresji ma ponad dwa wieki (jego początki to rok 1805). Algorytm j48 używany do klasyfikacji ma swoje korzenie w entropii informacji – praca Claude Shannon z roku 1948. Mamy algorytmy jeszcze starsze – k-means grupujący obiekty, bazuje na idei odległości euklidesowej która, wywodzi się ze starożytnej geometrii greckiej.
Jeśli ktoś miałby robić tu „lerning” to z pewnością nie maszyny ale człowiek. Komputer, jako doskonała maszyna licząca, policzy w sekundę to, co człowiek robiłby tygodniami. Nie nastąpiła żadna rewolucja w nauce – zyskaliśmy dostęp do szybkich maszyn liczących. Jeśli „maszin lerning” jest bazą „sztucznej inteligencji” to jak wygląda ona sama?
Eksploracja danych jest rzemiosłem. Polega na zastosowaniu znacznej ilości nauki i technologii, ale właściwe zastosowanie nadal obejmuje również sztukę. Żadna maszyna nie dobierze atrybutów w tak właściwy sposób jak zrobi to człowiek. Np. w handlu detalicznym atrybut „częstotliwość zakupów” może być bardziej miarodajny niż w relacjach B2B. W Stanach Zjednoczonych istnieją zawody w eksploracji danych (Data Mining Cup, GE-NFL Head Health Challenge, GEQuest) a nagrody za rozwiązanie konkretnych problemów ludzkości są bardzo wysokie (np. 10 milionów dolarów w wyzwaniu GE-NFL Head Health Challenge).